|
0.8
Sorting media using crowdsourcing.
|
Doxygen |
 |
|
0.8
Sorting media using crowdsourcing.
|
Doxygen |
|
Serves as an intermediary between the MySQLbase database in which HIT results are stored and CrowdFlower, our crowdsourcing provider. More...
 Collaboration diagram for crowdUser.CrowdManager:
Collaboration diagram for crowdUser.CrowdManager: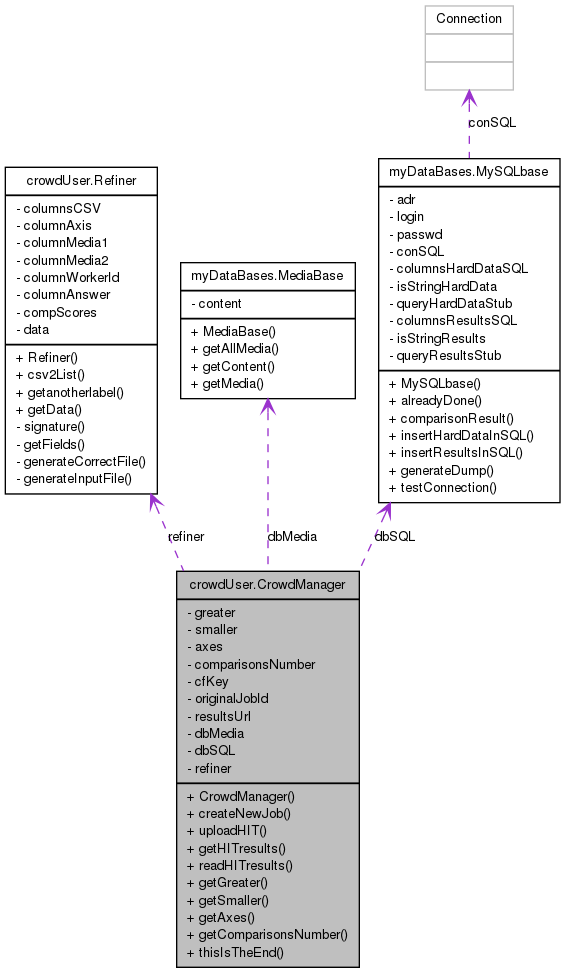 [legend]
[legend]Public Member Functions | |
| CrowdManager (Integer firstJobId, String key, String resultsUrl, MySQLbase baseSQL, MediaBase baseDIR, List< String > fieldsHardData) | |
| Creates an instance of the CrowdManager class. <../..> | |
| Integer | createNewJob () |
Creates a new job at CrowdFlower that is a copy of the "original" one (the one with the originalJobId identifier) and returns its identifier. <../..> | |
| void | uploadHIT (Integer jobId) |
| Uploads at CrowdFlower the csv file corresponding to the comparisons required. <../..> | |
| String | getHITresults (Integer jobId) |
Downloads results from the URL specified in the resultsUrl attribute and returns the path to it minus its extension (i.e '../data/HITresults/results42' for the results stored in the '../data/HITresults/results42.csv' file). <../..> | |
| void | readHITresults (String path) |
Adds the HIT results contained in the csv file in path to the dbSQL myDataBases.MySQLbase database. <../..> | |
| List< Integer > | getGreater () |
| Returns the value of greater. <../..> | |
| List< Integer > | getSmaller () |
| Returns the value of smaller. <../..> | |
| List< String > | getAxes () |
| Returns the value of axes. <../..> | |
| Integer | getComparisonsNumber () |
| Returns the value of comparisonsNumber. <../..> | |
Static Public Member Functions | |
| static void | thisIsTheEnd (String antechamberUrl, String results) |
Asks the Antechamber to send an email signaling the end of the Splitsort. <../..> | |
Private Attributes | |
| List< Integer > | greater |
| The ID of the media alleged to be "greater". <../..> | |
| List< Integer > | smaller |
| The ID of the media alleged to be "smaller". <../..> | |
| List< String > | axes |
| The axes along which each comparison must be performed. <../..> | |
| Integer | comparisonsNumber |
| The number of comparisons performed during the current iteration. <../..> | |
| String | cfKey |
| The key given by crowdFlower to authenticate yourself. <../..> | |
| Integer | originalJobId |
| The identifier of the "original" job, i.e the one from which every characteristics (webhook address, tags, cml configuration...) will be copied in all the jobs created during the current execution of CPS. <../..> | |
| String | resultsUrl |
| The number of jobs already submitted (a job is a group of HITs) <../..> | |
| MediaBase | dbMedia |
| The MediaBase instance in which the names of the media are stored. <../..> | |
| MySQLbase | dbSQL |
| The MySQLbase instance to which it is connected and in which HIT results must be stored. <../..> | |
| Refiner | refiner |
| The Refiner instance used to treat the result of the HITs. <../..> | |
Serves as an intermediary between the MySQLbase database in which HIT results are stored and CrowdFlower, our crowdsourcing provider.
This class performs several operations : after retrieving unknown comparisons, it submits them to the crowd using CrowdFlower's "self service". When the HITs are finished, it downloads the results from the Antechamber (see the online documentation), saves them, gives them to its Refiner instance (refiner) to parse them and sends them to dbSQL, a myDataBases.MySQLbase instance in which they are stored.
Once this is done, it uses refiner to reduce the noise in the hard results and thus to obtain refined results (more details in the Refiner documentation). These are then sent to dbSQL.
Definition at line 39 of file CrowdManager.java.
| crowdUser.CrowdManager.CrowdManager | ( | Integer | firstJobId, |
| String | key, | ||
| String | resultsUrl, | ||
| MySQLbase | baseSQL, | ||
| MediaBase | baseDIR, | ||
| List< String > | fieldsHardData | ||
| ) |
Creates an instance of the CrowdManager class.
Initializes all of its attributes, except the greater, smaller and axes attributes. Indeed, these are set afterward using affectation like CrowdManagerInstance.getGreater() = someArrayOfIntegers.
| firstJobId | The identifier of a job in your CrowdFlower account already configured. |
| key | The key given by CrowdFlower. |
| resultsUrl | The URL where results$JOB_ID.txt is, most likely that of the csv/ folder of the Antechamber. |
| baseSQL | The MySQLbase in which the results must be stored. |
| baseDIR | The MediaBase in which the name of the media sorted are stored |
| fieldsHardData | The fields of the CSV file returned by the Antechamber containing the HITs' hard results. |
Definition at line 110 of file CrowdManager.java.
{
this.comparisonsNumber = 0;
this.resultsUrl = resultsUrl;
this.greater = new ArrayList<Integer>();
this.smaller = new ArrayList<Integer>();
this.axes = new ArrayList<String>();
this.originalJobId = firstJobId;
this.cfKey = key;
this.dbSQL = baseSQL;
this.dbMedia = baseDIR ;
this.refiner = new Refiner(fieldsHardData);
};
| Integer crowdUser.CrowdManager.createNewJob | ( | ) |
Creates a new job at CrowdFlower that is a copy of the "original" one (the one with the originalJobId identifier) and returns its identifier.
Creates a copy of of the original job using a http POST to the address given in Crowdflower's documentation. When the POST is done, CrowdFlower returns a JSON formatted string containing, among other things, the identifier of the job.
Definition at line 139 of file CrowdManager.java.
{
Integer id = 0;
String postUrl = "http://api.crowdflower.c../..bs/" + this.originalJobId
+ "/copy.json?key=" + this.cfKey ;
// posting the request
try
{
URL url = new URL(postUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
// Building an HTTP request
conn.setDoOutput(true);
conn.setRequestMethod("POST");
conn.connect();
// getting the answer from CrowdFlower and reading the "id" field
BufferedReader rd = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line, idString = "";
while ((line = rd.readLine()) != null)
if (line.contains('"'+"id"+'"'))
// we go to the index of ' "id": ' and read the number. In order no to take '"id":', 5 is added.
for (int i = line.lastIndexOf('"' +"id"+'"')+5; i<line.length(); i++)
if ( line.charAt(i) == ',' )
break;
else
idString += line.charAt(i) ;
id = Integer.parseInt(idString);
rd.close();
} catch (Exception e) { e.printStackTrace(); }
return id;
}
| List<String> crowdUser.CrowdManager.getAxes | ( | ) |
Returns the value of axes.
Definition at line 382 of file CrowdManager.java.
{ return this.axes; }
| Integer crowdUser.CrowdManager.getComparisonsNumber | ( | ) |
Returns the value of comparisonsNumber.
Definition at line 390 of file CrowdManager.java.
{ return this.comparisonsNumber; }
| List<Integer> crowdUser.CrowdManager.getGreater | ( | ) |
Returns the value of greater.
Definition at line 366 of file CrowdManager.java.
{ return this.greater ; }
| String crowdUser.CrowdManager.getHITresults | ( | Integer | jobId | ) |
Downloads results from the URL specified in the resultsUrl attribute and returns the path to it minus its extension (i.e '../data/HITresults/results42' for the results stored in the '../data/HITresults/results42.csv' file).
First, you have to make sure the results are at the given address: was the correct webhook sent at the Antechamber ? Is the processing of the raw results finished? An email is sent when both of these operations are finisehded.
If so, use this method to download the results$JOB_ID.txt file containing the answers of the workers and to save it as ../data/results/results$JOB_ID.csv.
| jobId | The identifier of the job used to obtain comparisons. It is given by CrowdFlower's web application when a new job is created as well as the createNewJob() method. |
Definition at line 259 of file CrowdManager.java.
{
try
{
// creating connection
String urlString = this.resultsUrl + "csv/" + jobId + ".txt";
System.out.println(urlString);
URL url = new URL(urlString);
System.out.println("Opening connection to " + urlString + "...");
// reading input
InputStream is = url.openStream();
System.out.flush();
// creating results$JOB_ID.csv file
FileOutputStream fos=null;
fos = new FileOutputStream("../data/HITresults/results" + jobId + ".csv");
// writing to file
int oneChar, count=0;
while ((oneChar=is.read()) != -1)
{
fos.write(oneChar);
count++;
}
// close everything
is.close();
fos.close();
System.out.println("csv results file downloaded, " + count + " byte(s) copied");
}
catch (Exception e) { e.printStackTrace(); }
// return the name of the file minus ".csv"
return "results" + jobId ;
}
| List<Integer> crowdUser.CrowdManager.getSmaller | ( | ) |
Returns the value of smaller.
Definition at line 374 of file CrowdManager.java.
{ return this.smaller; }
| void crowdUser.CrowdManager.readHITresults | ( | String | path | ) |
Adds the HIT results contained in the csv file in path to the dbSQL myDataBases.MySQLbase database.
The hard results are sent to refiner in order it to parse them. They are then sent to dbSQL to be stored. At this point, dbSQL contains all of the results obtained.
After that, results are refined by refiner in order to reduce the noise, see the Refiner.getanotherlabel method for more details on how it is done. Again, when this is over, refined results are stored in dbSQL.
| path | The path to the csv file containing the HIT results |
Definition at line 306 of file CrowdManager.java.
{
List<String[]> entries ;
// retrieve hard data from the csv file
this.refiner.csv2List(path) ;
entries = this.refiner.getData() ;
this.dbSQL.insertHardDataInSQL(entries);
// retrieve good data from the refiner
this.refiner.getanotherlabel() ;
entries = this.refiner.getData() ;
this.dbSQL.insertResultsInSQL(entries,this.dbMedia) ;
}
| static void crowdUser.CrowdManager.thisIsTheEnd | ( | String | antechamberUrl, |
| String | results | ||
| ) | [static] |
Asks the Antechamber to send an email signaling the end of the Splitsort.
Uses an http POST powered by java.net to the correct URL to ask the Antechamber to send an e-mail containing the identifier of this last job, information on how to retrieve the results and the content of the results String as an attachment.
| antechamberUrl | The url to which the information must be posted |
| results | Content to be sent as an attachment file along with the e-mail. The name it will have is set in the Antechamber. |
Definition at line 333 of file CrowdManager.java.
{
try
{
URL url = new URL(antechamberUrl);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
// Building an HTTP request
conn.setDoOutput(true);
conn.setRequestMethod("POST");
OutputStreamWriter osw = new OutputStreamWriter(conn.getOutputStream());
String data = URLEncoder.encode("signal", "UTF-8") + "=" + URLEncoder.encode("sort_finished","UTF-8")
+ "&" + URLEncoder.encode("payload", "UTF-8") + "=" + URLEncoder.encode(results, "UTF-8");
osw.write(data);
osw.flush();
osw.close();
// getting the answer from CrowdFlower
BufferedReader rd = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
while ((line = rd.readLine()) != null) {
System.out.println(line);
}
rd.close();
} catch (Exception e) { e.printStackTrace(); }
}
| void crowdUser.CrowdManager.uploadHIT | ( | Integer | jobId | ) |
Uploads at CrowdFlower the csv file corresponding to the comparisons required.
The csv (Comma Separated File) file is first generated. The fields used are NOT set using the config.xml, they are hard coded. Indeed, CrowdFlower needs nothing else than the axis along which the comparison is performed, the identifier of the media (so they can be sent back), their names (so they can be displayed) and a text associated with each one (for example to respect a CC-BY license).
Once generated, it is sent using a PUT http request containing the csv file, the identifier of the job (jobNUmber) and the key given by CrowdFlower (the key parameter).
| jobId | The identifier of the job that will receive the data contained in the csv file. |
Definition at line 187 of file CrowdManager.java.
{
this.comparisonsNumber += this.greater.size() ;
String post = "";
// writing the .csv file and the post String
try{
BufferedWriter fichier = new BufferedWriter
(new FileWriter("../data/HITdata/" + jobId + ".csv"));
String line = "axis,idMedia1,idMedia2,urlMedia1,urlMedia2,miscData1,miscData2";
fichier.write(line);
fichier.newLine();
post += line ;
for (int i=0; i<this.greater.size(); i++)
{
line = this.axes.get(i) + "," + this.greater.get(i) + "," + this.smaller.get(i) +
"," + this.dbMedia.getMedia(this.greater.get(i)) +
"," + this.dbMedia.getMedia(this.smaller.get(i)) +
",\"" + this.dbMedia.getContent().get(this.greater.get(i)).get("miscData") +
"\",\"" + this.dbMedia.getContent().get(this.smaller.get(i)).get("miscData") + "\"";
fichier.write(line);
fichier.newLine();
post += "\n" + line ;
}
fichier.close();
}
catch (Exception e) { e.printStackTrace(); }
// posting the file
try
{
URL url = new URL("http://api.crowdflower.c../..bs/" + jobId +
"/upload.json?key=" + this.cfKey);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
// Building an HTTP request
conn.setDoOutput(true);
conn.setRequestMethod("PUT");
conn.setRequestProperty("Content-Type", "text/csv");
OutputStreamWriter osw = new OutputStreamWriter(conn.getOutputStream());
osw.write(post);
osw.flush();
osw.close();
// getting the answer from CrowdFlower
BufferedReader rd = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line;
while ((line = rd.readLine()) != null) {
System.out.println(line);
}
rd.close();
} catch (Exception e) { e.printStackTrace(); }
}
List<String> crowdUser.CrowdManager.axes [private] |
The axes along which each comparison must be performed.
Definition at line 58 of file CrowdManager.java.
String crowdUser.CrowdManager.cfKey [private] |
The key given by crowdFlower to authenticate yourself.
If you have an account (and you definitively have to), it is available here.
Definition at line 67 of file CrowdManager.java.
Integer crowdUser.CrowdManager.comparisonsNumber [private] |
The number of comparisons performed during the current iteration.
Definition at line 62 of file CrowdManager.java.
MediaBase crowdUser.CrowdManager.dbMedia [private] |
The MediaBase instance in which the names of the media are stored.
Definition at line 82 of file CrowdManager.java.
MySQLbase crowdUser.CrowdManager.dbSQL [private] |
The MySQLbase instance to which it is connected and in which HIT results must be stored.
Definition at line 86 of file CrowdManager.java.
List<Integer> crowdUser.CrowdManager.greater [private] |
The ID of the media alleged to be "greater".
They are to be compared with those of the "smaller" attribute through HITs.
Definition at line 49 of file CrowdManager.java.
Integer crowdUser.CrowdManager.originalJobId [private] |
The identifier of the "original" job, i.e the one from which every characteristics (webhook address, tags, cml configuration...) will be copied in all the jobs created during the current execution of CPS.
Definition at line 74 of file CrowdManager.java.
Refiner crowdUser.CrowdManager.refiner [private] |
The Refiner instance used to treat the result of the HITs.
Definition at line 90 of file CrowdManager.java.
String crowdUser.CrowdManager.resultsUrl [private] |
The number of jobs already submitted (a job is a group of HITs)
Definition at line 78 of file CrowdManager.java.
List<Integer> crowdUser.CrowdManager.smaller [private] |
The ID of the media alleged to be "smaller".
They are to be compared with those of the "greater" attribute through HITs.
Definition at line 54 of file CrowdManager.java.

